

Le choix d’une architecture d’API est une décision structurante qui influence non seulement la performance technique d’une application, mais aussi la productivité des équipes de développement sur le long terme. J’ai vu les standards évoluer pour répondre à des besoins de flexibilité toujours plus croissants. Si REST domine le marché par sa robustesse et sa simplicité historique, GraphQL est venu bousculer les codes en proposant une approche radicalement différente centrée sur le client. Comprendre les nuances entre ces deux technologies est devenu indispensable pour tout architecte ou développeur souhaitant bâtir des systèmes évolutifs.
Comprendre les fondamentaux : définitions et architectures
Avant de plonger dans les détails techniques, je pense qu’il est crucial de revenir aux définitions de base de ces deux méthodes de communication. Bien qu’elles servent le même objectif, leur philosophie de conception diverge totalement.
Qu’est-ce qu’une API REST ? Le standard basé sur les ressources
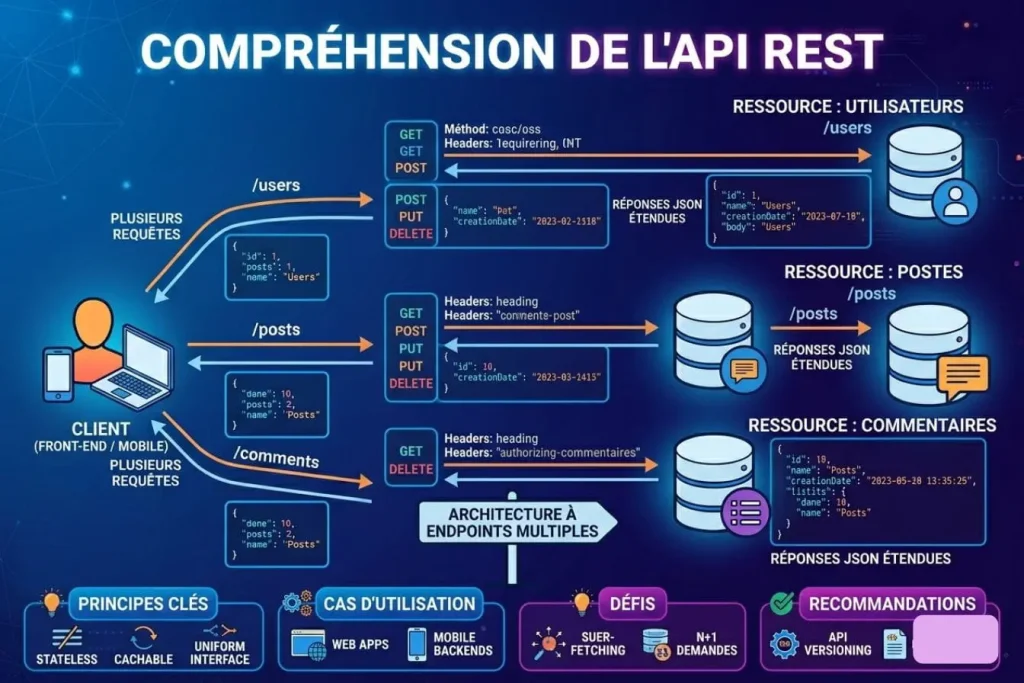
REST (Representational State Transfer) est un style d’architecture introduit au début des années 2000. Je le définis souvent comme une approche orientée « ressources ». Dans ce modèle, chaque entité (un utilisateur, un article, un produit) est identifiée par une URL unique. Pour interagir avec ces données, on utilise les méthodes standards du protocole HTTP (GET, POST, PUT, DELETE). C’est un système prévisible, stable et très facile à comprendre, car il s’appuie sur la structure même du Web. Sa force réside dans sa capacité à séparer proprement le client du serveur, permettant ainsi une grande interopérabilité.
Vitesse supérieure : comment l’accélérateur transforme votre startup en scale-up ?
Qu’est-ce que GraphQL ? Le langage de requête moderne de Facebook
GraphQL, créé par Facebook en 2012 et rendu public en 2015, n’est pas un simple style d’architecture mais un langage de requête. Contrairement à REST, il ne se concentre pas sur des ressources isolées mais sur un graphe de données interconnectées. Je le compare souvent à un menu de restaurant à la carte : au lieu de recevoir un plat préparé à l’avance par le serveur (le point de terminaison REST), le client précise exactement les ingrédients (les champs) dont il a besoin. Le serveur GraphQL répond alors avec une structure de données qui correspond précisément à la demande, éliminant ainsi tout superflu.
Les points communs : protocole HTTP et échange de données JSON
Malgré leurs divergences philosophiques, je tiens à rappeler que ces deux technologies partagent un socle commun. Elles utilisent toutes deux le protocole HTTP comme couche de transport. De plus, le format d’échange de données privilégié est presque exclusivement le JSON. Que vous fassiez du REST ou du GraphQL, vous bénéficiez donc d’un format de données léger, lisible par l’homme et supporté par quasiment tous les langages de programmation modernes. Cette proximité facilite grandement la migration de l’un vers l’autre ou leur cohabitation au sein d’un même écosystème.
Les différences techniques majeures dans le transfert de données
C’est dans la gestion des flux de données que les différences deviennent palpables pour les développeurs au quotidien. La manière dont on interroge le serveur change du tout au tout.
Gestion des points de terminaison (endpoints) : multiple vs unique
C’est sans doute la différence la plus flagrante. En REST, vous gérez une multitude d’URL. Pour récupérer les détails d’un utilisateur et ses articles, vous devrez peut-être appeler /users/1 puis /users/1/posts. À l’inverse, GraphQL utilise un point de terminaison unique (généralement /graphql). Toutes les requêtes, quelles que soient les données visées, sont envoyées à cette URL unique via une requête POST contenant le corps de la demande. Cette centralisation simplifie la gestion des accès et réduit la complexité de l’infrastructure côté client.
Over-fetching et Under-fetching : le contrôle précis des données
REST souffre souvent de deux maux que je rencontre fréquemment lors d’audits de performance. L’over-fetching survient lorsque le serveur renvoie trop de données (par exemple, 50 champs pour un utilisateur alors que vous ne voulez afficher que son nom). L’under-fetching, à l’inverse, oblige à multiplier les appels car le premier point de terminaison ne contenait pas assez d’informations. GraphQL résout magistralement ce problème. Le client définit sa propre structure de réponse, ce qui garantit qu’aucune donnée inutile n’est transférée sur le réseau, optimisant ainsi la bande passante.
Croissance exponentielle ou stabilité : quel ADN business correspond à votre projet ?
Le système de typage et le schéma : la flexibilité face à la structure
GraphQL impose l’utilisation d’un schéma fortement typé (Schema Definition Language). Ce schéma sert de contrat entre le client et le serveur. Je trouve cette approche particulièrement sécurisante : si vous demandez un champ qui n’existe pas ou si vous envoyez un mauvais type de donnée, l’erreur est détectée immédiatement. REST est plus souple, voire parfois trop permissif. Bien que des outils comme Swagger ou OpenAPI permettent de documenter les API REST, cette validation n’est pas nativement intégrée au processus de requête comme c’est le cas avec GraphQL.
Performance et optimisation des requêtes réseau
La performance est le nerf de la guerre dans le développement web moderne. Ici, chaque technologie possède des atouts qui dépendent du contexte de l’application.
Round-trips : réduire le nombre d’allers-retours vers le serveur
Dans une application complexe, REST peut forcer le client à effectuer de nombreux allers-retours (round-trips) pour construire une vue complète. Sur une connexion mobile instable, chaque requête supplémentaire ajoute de la latence. Grâce à sa capacité à agréger les données, GraphQL permet de récupérer des ressources liées en une seule requête. Je constate que cela améliore considérablement la réactivité perçue de l’interface utilisateur, car le temps d’attente cumulé lié à l’établissement des connexions HTTP est drastiquement réduit.
Mise en cache (Caching) : l’avantage natif de REST sur GraphQL
C’est le point faible historique de GraphQL. Comme tout passe par un point de terminaison unique en POST, la mise en cache au niveau du navigateur ou du CDN est complexe. REST, en revanche, utilise des URL distinctes et les méthodes GET, ce qui permet de profiter nativement de la mise en cache HTTP. Un navigateur sait qu’il peut mettre en cache la réponse de /products/123. Pour obtenir un résultat similaire en GraphQL, je vous conseille d’utiliser des outils tiers comme Apollo Client ou Relay, qui gèrent leur propre cache côté client, mais cela ajoute une couche de complexité technique supplémentaire.
Charge utile (Payload) et rapidité de réponse sur mobile
Pour les utilisateurs mobiles, la taille des données transférées est cruciale. En permettant de supprimer les champs inutiles, GraphQL réduit la taille du payload (la charge utile). Cependant, je nuance souvent ce propos : l’analyse de la requête (parsing) côté serveur GraphQL est plus gourmande en ressources que le simple routage de REST. Pour une application simple avec peu de données, REST peut s’avérer plus rapide. Mais dès que la structure de données devient profonde et complexe, le gain de poids offert par GraphQL prend le dessus et améliore l’expérience utilisateur sur smartphone.
Expérience développeur et maintenance des API
La facilité de maintenance et la satisfaction des développeurs sont des critères essentiels pour la réussite d’un projet sur 15 ans ou plus.
Documentation et introspection : l’auto-documentation de GraphQL
L’un des aspects les plus brillants de GraphQL est l’introspection. Le serveur peut être interrogé pour fournir sa propre structure. Cela donne naissance à des outils comme GraphiQL ou Playground, où les développeurs peuvent tester des requêtes avec de l’autocomplétion en temps réel. En REST, la documentation est souvent un effort séparé qui a tendance à se désynchroniser du code réel. Avec GraphQL, la documentation est le reflet exact du code, ce qui réduit les frictions entre les équipes front-end et back-end.
Gestion du versioning : évolution fluide ou changements de versions
En REST, on voit souvent des URL comme /api/v1/ ou /api/v2/. Lorsqu’un changement majeur intervient, on crée une nouvelle version pour ne pas casser les clients existants. GraphQL propose une approche différente : le versioning par obsolescence. Au lieu de changer d’URL, on marque certains champs comme « dépréciés ». Le schéma continue d’évoluer de manière continue. Je trouve cette méthode plus respectueuse de la compatibilité ascendante, car elle permet aux anciens clients de fonctionner tout en incitant doucement les nouveaux à utiliser les nouveaux champs.
Courbe d’apprentissage et écosystème d’outils
REST est d’une simplicité désarmante. N’importe quel développeur junior peut comprendre le fonctionnement d’une URL et d’une méthode GET. GraphQL, en revanche, possède une courbe d’apprentissage plus abrupte. Il faut comprendre le schéma, les résolveurs, les types, les mutations et les fragments. De plus, l’écosystème (Apollo, Yoga, Relay) est vaste et peut être intimidant. Je recommande souvent de ne pas sous-estimer le temps nécessaire pour que vos équipes maîtrisent les subtilités de GraphQL avant de l’adopter sur un projet critique.
Cas d’utilisation : quand privilégier REST ou GraphQL ?
Il n’y a pas de « meilleure » technologie dans l’absolu, seulement des outils adaptés à des besoins spécifiques. Voici ma vision pour orienter votre choix.
Pourquoi choisir REST pour les projets simples et le caching public ?
REST reste la solution idéale pour de nombreux scénarios. Si votre application est relativement simple, avec peu de relations complexes entre les données, REST sera plus rapide à mettre en place. Je le préconise également pour les API publiques destinées à être consommées par des tiers, car tout le monde sait comment utiliser du REST. Enfin, pour les sites où le contenu change peu et où la mise en cache agressive est vitale (comme un catalogue produit statique), la robustesse du cache HTTP de REST est un avantage imbattable.
Pourquoi opter pour GraphQL dans les applications complexes et microservices ?
Si vous construisez un tableau de bord complexe, une application de type réseau social ou une plateforme e-commerce avec de multiples variantes de produits, GraphQL est un sauveur. Il excelle lorsque les besoins du front-end varient énormément d’une page à l’autre. Dans une architecture de microservices, GraphQL peut aussi servir de couche d’agrégation (API Gateway), permettant de réunir plusieurs sources de données disparates sous une interface unique et cohérente pour le client.
L’approche hybride : faire cohabiter les deux technologies
Il est tout à fait possible, et parfois souhaitable, de ne pas choisir. J’ai travaillé sur des projets où REST gérait les transferts de fichiers volumineux et les authentifications simples, tandis que GraphQL s’occupait de la récupération des données métier complexes. Cette approche hybride permet de tirer le meilleur des deux mondes. Vous pouvez par exemple exposer une API REST héritée pour la compatibilité, tout en développant une nouvelle interface GraphQL pour vos besoins mobiles modernes. La flexibilité doit primer sur le dogmatisme technologique.
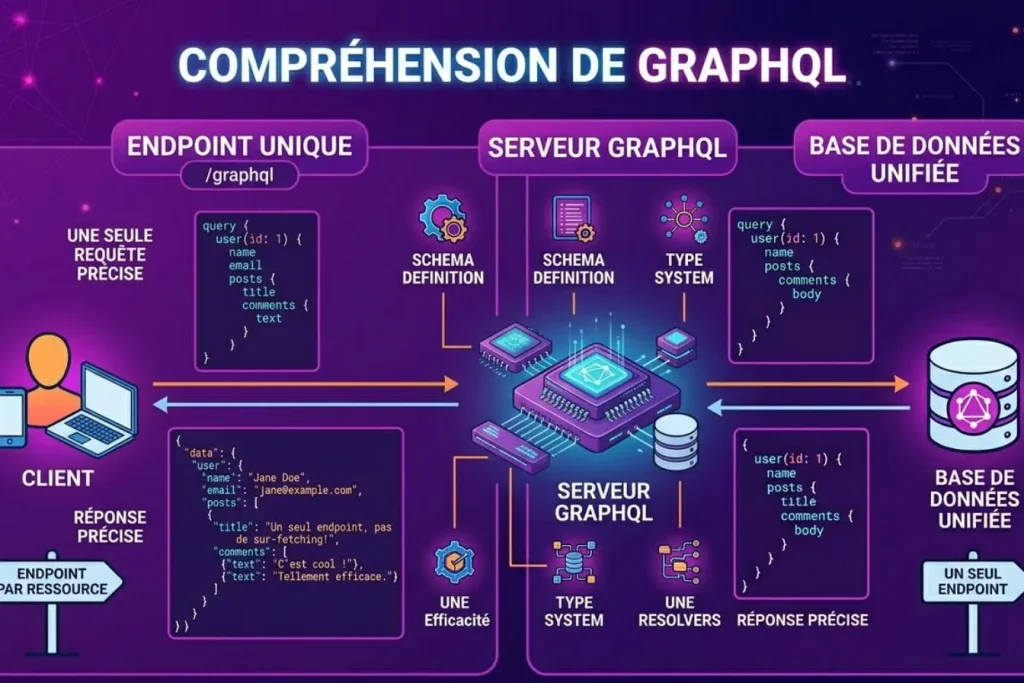
Tableau comparatif : API REST vs GraphQL en un coup d’œil
Pour vous aider à synthétiser ces informations, j’ai dressé ce tableau qui résume les points de friction et les forces de chaque système.
| Caractéristique | API REST | GraphQL |
|---|---|---|
| Points de terminaison | Multiples (URL par ressource) | Unique (généralement /graphql) |
| Récupération des données | Fixée par le serveur | Définie par le client |
| Mise en cache | Native et facile via HTTP | Complexe, nécessite des outils tiers |
| Versioning | Explicite (v1, v2, etc.) | Évolution continue (dépréciation) |
| Sur-récupération | Risque élevé (Over-fetching) | Éliminée par conception |
| Apprentissage | Rapide et intuitif | Plus long et technique |
Critères de sélection selon les besoins de votre projet web
Pour conclure cette réflexion, je vous suggère de poser les questions suivantes à votre équipe avant de trancher. Si votre priorité est la rapidité de mise en œuvre et que vous avez des besoins de mise en cache simples, restez sur REST. Si vous développez une application riche avec des données très imbriquées et que vous voulez offrir une expérience optimale sur mobile, GraphQL est sans doute votre meilleur allié. Dans tous les cas, gardez en tête que la meilleure API est celle qui répond aux besoins de vos utilisateurs tout en restant maintenable par vos développeurs. Ne succombez pas à la mode technologique sans une analyse concrète de vos flux de données réels.






0 commentaires