

L’intelligence artificielle générative a transformé notre manière d’interagir avec l’information, mais elle se heurte souvent à une limite de taille : la fraîcheur et la fiabilité de ses connaissances. Le RAG, ou Génération Augmentée par Récupération, s’impose aujourd’hui comme la solution technique incontournable pour combler ce fossé. Imaginez une IA qui ne se contenterait pas de réciter des leçons apprises lors de son entraînement, mais qui serait capable d’ouvrir un livre de référence spécifique pour répondre à une question précise. Le RAG agit comme un pont entre la puissance de raisonnement des grands modèles de langage et l’exactitude des données privées ou récentes. C’est une avancée majeure qui permet de passer d’une IA « savante » à une IA « experte » capable de consulter des sources vérifiables en temps réel.
Définition et concept de la Génération Augmentée par Récupération
Le concept de RAG repose sur une idée simple mais puissante : plutôt que de demander à un modèle de langage (LLM) de tout mémoriser, on lui fournit les outils pour aller chercher l’information là où elle se trouve. Je compare souvent cela à un étudiant passant un examen : le modèle de base travaille de mémoire, tandis que le RAG lui donne droit à ses manuels. Cette approche hybride combine deux mondes distincts de l’informatique : la recherche d’information traditionnelle et la génération de texte par IA.
Pourquoi le RAG est-il une révolution pour les LLM ?
La révolution réside dans la fin de la « boîte noire ». Un modèle classique comme GPT-4 a une date de fin de connaissances fixe. Si vous l’interrogez sur un événement survenu hier, il risque d’inventer une réponse. Le RAG brise cette barrière temporelle. En permettant au modèle d’accéder à des documents externes avant de formuler sa réponse, nous transformons l’IA en un assistant capable de citer ses sources. Cette mutation change radicalement la confiance que nous pouvons accorder aux outils d’IA, les rendant enfin exploitables dans des contextes professionnels où l’erreur n’est pas permise.
Le lien entre modèles de langage et bases de données externes
Dans une architecture RAG, le modèle de langage ne travaille plus seul. Il est couplé à une base de données qui contient des informations spécifiques : vos rapports annuels, vos procédures internes ou les dernières actualités boursières. Lorsqu’une requête est formulée, le système interroge d’abord cette base pour extraire les passages les plus pertinents. Ces extraits sont ensuite injectés dans le contexte du modèle. Le LLM utilise alors sa capacité de synthèse pour rédiger une réponse cohérente en se basant strictement sur les faits récupérés. C’est cette synergie qui garantit la pertinence de l’information produite.
Comprendre la différence entre Fine-tuning et RAG
Il est fréquent de confondre ces deux méthodes d’optimisation. Le Fine-tuning consiste à réentraîner légèrement le modèle pour lui apprendre un style ou un domaine spécifique, un processus long et coûteux. À l’inverse, le RAG ne modifie pas le modèle lui-même, il lui donne simplement de nouvelles fiches de lecture.
| Caractéristique | Fine-tuning | RAG (Génération Augmentée) |
|---|---|---|
| Coût | Élevé (puissance de calcul) | Modéré (stockage et recherche) |
| Mise à jour des données | Nécessite un nouveau cycle | Instantanée (ajout de documents) |
| Sources | Non citables | Identifiables et vérifiables |
| Objectif | Adapter le ton ou le vocabulaire | Apporter des connaissances fraîches |
Comment fonctionne techniquement une architecture RAG ?
Pour comprendre l’aspect technique, je décompose souvent le processus en trois étapes clés. C’est une mécanique de précision qui demande une préparation méticuleuse des données en amont.
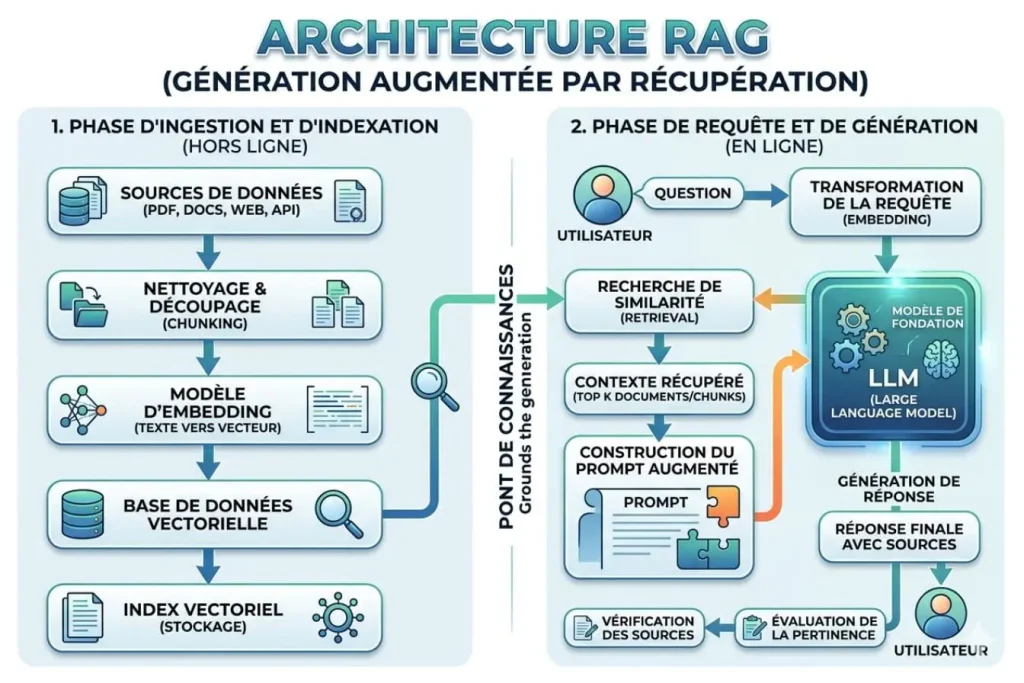
L’étape de récupération : l’importance de la recherche sémantique
La première étape consiste à trouver la bonne information. Contrairement à une recherche par mots-clés classique (type Ctrl+F), le RAG utilise la recherche sémantique. Il ne cherche pas des termes exacts, mais des concepts. Si vous posez une question sur le « bien-être au travail », le système sera capable de récupérer des documents traitant de la « qualité de vie au bureau » ou de « l’ergonomie », car il comprend que le sens est proche. Cette capacité à saisir l’intention de l’utilisateur est le cœur battant du RAG.
IA et ROI : le guide pour booster vos performances marketing grâce aux algorithmes intelligents.
Le rôle des bases de données vectorielles et des embeddings
Pour que cette recherche sémantique fonctionne, les textes sont transformés en vecteurs mathématiques, appelés « embeddings ». Ces vecteurs sont stockés dans des bases de données spécifiques (Vector Databases). Chaque document devient un point dans un espace multidimensionnel. Lorsque vous posez une question, elle est aussi transformée en point mathématique. Le système identifie les points les plus proches spatialement de votre question, ce qui correspond statistiquement aux informations les plus pertinentes. C’est une prouesse mathématique qui permet de traiter des millions de documents en quelques millisecondes.
L’étape de génération : enrichir le prompt avec des données fraîches
Une fois les passages pertinents identifiés, ils sont intégrés au « prompt » (la consigne) envoyé à l’IA. La structure ressemble alors à ceci : « Voici trois extraits de notre règlement interne. En te basant uniquement sur ces éléments, réponds à la question suivante… ». Le modèle de langage n’utilise alors ses connaissances internes que pour structurer la phrase et respecter la grammaire, tandis que la substance de la réponse provient exclusivement des données récupérées. On parle alors de génération « augmentée » car le contexte du modèle a été artificiellement agrandi par les informations externes.
Quels sont les avantages concrets du RAG pour les entreprises ?
L’adoption du RAG n’est pas qu’une mode technique ; elle répond à des besoins business fondamentaux que les modèles d’IA standards ne pouvaient satisfaire jusqu’alors.
Réduction drastique des hallucinations de l’intelligence artificielle
L’hallucination est le talon d’Achille de l’IA générative : le modèle invente des faits avec un aplomb déconcertant. Le RAG agit comme un garde-fou. En forçant le modèle à s’appuyer sur des documents réels, on réduit considérablement le risque d’invention. Si l’information n’est pas dans la base de données, le modèle est programmé pour dire qu’il ne sait pas, évitant ainsi la propagation de fausses informations qui pourraient nuire à la crédibilité de votre entreprise.
Accès à des données en temps réel sans réentraînement coûteux
Pour une entreprise dont les stocks ou les tarifs changent quotidiennement, un modèle classique est obsolète en 24 heures. Avec le RAG, il suffit de mettre à jour le document dans la base de données vectorielle pour que l’IA en soit immédiatement informée. Cette agilité permet de créer des systèmes d’assistance toujours à jour, sans avoir à investir des dizaines de milliers d’euros dans des cycles d’entraînement machine complexes et énergivores.
Confidentialité et sécurité : garder le contrôle sur les informations internes
C’est un point qui me tient particulièrement à cœur en tant que consultant. Le RAG permet d’utiliser la puissance des modèles publics (comme ceux d’OpenAI ou de Google) tout en gardant vos données sensibles chez vous. Les documents confidentiels restent dans votre base de données sécurisée. Seuls les extraits pertinents sont envoyés au modèle pour analyse, et souvent de manière anonymisée. Le contrôle d’accès devient granulaire : vous pouvez configurer le système pour que l’IA ne réponde qu’en fonction des documents auxquels l’utilisateur a légalement accès en interne.
Citations et sources : apporter de la transparence aux réponses de l’IA
L’un des plus grands plaisirs pour un utilisateur est de pouvoir vérifier l’information. Un système RAG bien conçu affiche systématiquement les sources utilisées pour générer la réponse.
- Vérification simplifiée : Un lien direct vers le PDF source.
- Crédibilité renforcée : La preuve que l’IA n’invente rien.
- Auditabilité : La capacité de comprendre pourquoi l’IA a donné cette réponse précise.
Les principaux cas d’usage du RAG aujourd’hui
Je vois le RAG s’immiscer dans tous les secteurs où l’expertise documentaire est valorisée. Ce n’est plus seulement un gadget de tech, c’est un outil de production.
Chatbots intelligents et services clients augmentés
Les agents conversationnels de première génération étaient souvent frustrants car limités à des scénarios pré-écrits. Un chatbot propulsé par le RAG peut consulter toute la documentation technique d’un produit complexe pour répondre à une question très spécifique d’un client. L’expérience client devient fluide et ultra-personnalisée, réduisant la charge de travail des centres d’appels qui ne gèrent plus que les cas les plus critiques nécessitant une empathie humaine.
Analyse documentaire complexe et recherche juridique ou médicale
Dans les professions réglementées, éplucher des milliers de pages de jurisprudence ou d’études cliniques prend un temps infini. Le RAG permet d’interroger instantanément un corpus massif de textes légaux pour en extraire des synthèses précises. Un avocat peut ainsi demander les précédents de décisions sur un sujet précis et obtenir une réponse étayée par les articles de loi exacts en quelques secondes, ce qui constitue un gain de productivité monumental.
GPT-4o décrypté : pourquoi ce modèle marque un tournant historique pour l’IA ?
Aide à la décision et gestion des connaissances en interne
Trop souvent, la connaissance d’une entreprise est éparpillée dans des emails, des fichiers SharePoint ou des dossiers partagés oubliés. Le RAG permet d’unifier ce « cerveau collectif ». En indexant l’ensemble de la base de connaissances interne, n’importe quel collaborateur peut poser une question complexe sur une procédure passée et obtenir une réponse cohérente. Le partage du savoir devient instantané et transparent, brisant les silos qui ralentissent habituellement les grandes organisations.
Quels sont les défis et limites de la mise en œuvre du RAG ?
Malgré ses promesses, le RAG n’est pas une baguette magique. Son efficacité dépend de plusieurs facteurs critiques que je surveille de près lors de chaque déploiement.

La qualité des données sources : le principe du « Garbage In, Garbage Out »
Si vos documents internes sont contradictoires, mal structurés ou obsolètes, l’IA produira des réponses de mauvaise qualité. Le RAG est un miroir de votre gestion documentaire. Une phase de nettoyage et de curation des données est indispensable avant toute mise en production. Je recommande toujours de commencer par un périmètre restreint mais propre plutôt que de vouloir indexer tout un serveur en désordre.
Optimisation du fenêtrage (chunking) pour une meilleure pertinence
La manière dont vous découpez vos documents en petits morceaux (le « chunking ») est un art subtil. Si les morceaux sont trop petits, ils perdent leur contexte. S’ils sont trop gros, ils diluent l’information pertinente et risquent de dépasser la capacité de mémoire du modèle. Trouver la taille idéale de ces segments de texte est crucial pour la précision du système. C’est souvent par des tests itératifs que l’on parvient à équilibrer la précision de la récupération et la clarté de la génération.
Coûts d’infrastructure et latence des requêtes hybrides
Le RAG ajoute une étape supplémentaire au processus classique de l’IA : la phase de recherche. Cela peut induire une légère latence. De plus, maintenir une base de données vectorielle performante et effectuer des recherches sémantiques répétées a un coût financier.
- Latence : Un temps de réponse légèrement supérieur à un LLM pur.
- Maintenance : La nécessité de surveiller la synchronisation de la base de données.
- Infrastructure : Le besoin de serveurs capables de gérer des calculs de proximité vectorielle rapides.
Cependant, ces coûts sont souvent dérisoires comparés au gain de temps humain et à la fiabilité gagnée. Le RAG représente aujourd’hui l’état de l’art pour quiconque souhaite transformer une intelligence artificielle généraliste en un outil professionnel sur mesure.





0 commentaires